
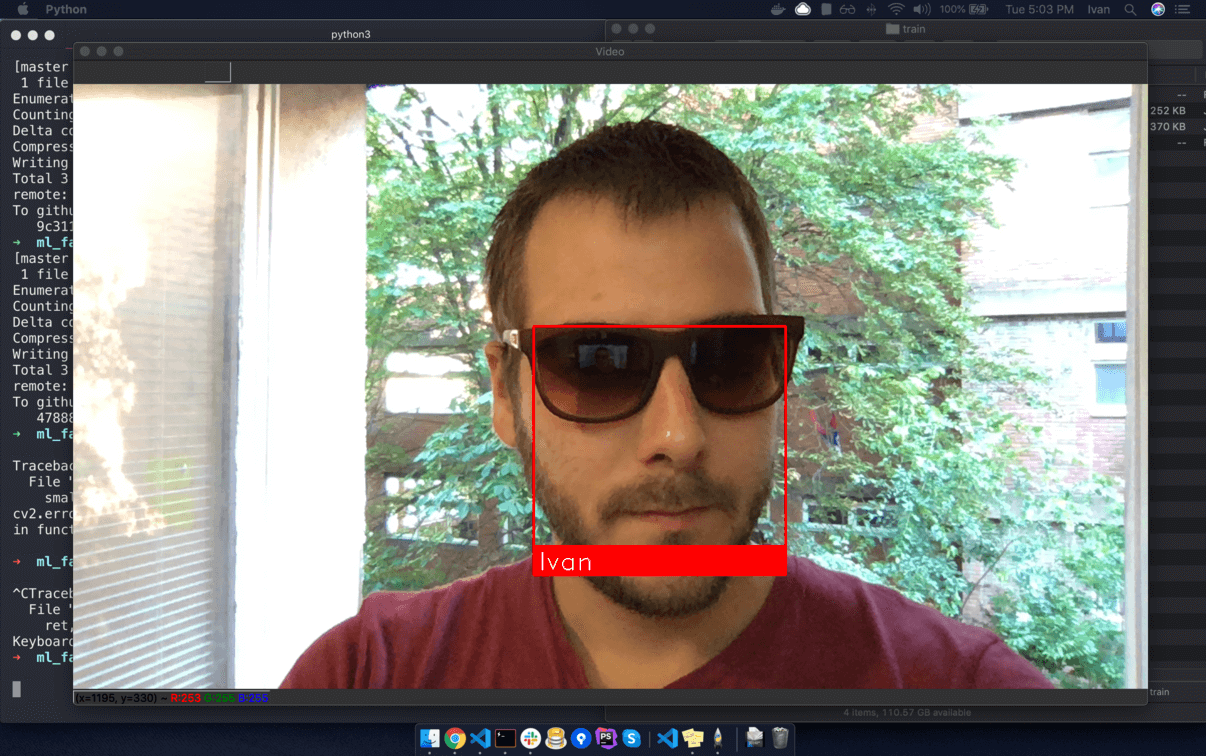
This is a example of running face recognition on live video from your webcam.
You can download project at github
We will use library https://github.com/ageitgey/face_recognition
Face Recognition is built using dlib's state-of-the-art face recognition built with deep learning. The model has an accuracy of 99.38%
We will use a simple face_recognition command line tool that lets us do face recognition on a folder of images from the command line!
File: facerec_from_webcam_faster.py
Train model:
Prepare a set of images of the known people you want to recognize. Organize the images in a single directory with a sub-directory for each known person.
/images/train/{Person Name}/image.jpg
-
train
-
Ivan
- image1.jpg
-
John
- image1.jpg
-
Ivan
Image naming does not matter...
Folder name will be used as label
Train image example
/images/train/Ivan/1.jpg

Run
python3 facerec_from_webcam_faster.py
File:
facerec_from_webcam_faster.py
import face_recognition
import cv2
import numpy as np
# Get a reference to webcam #0 (the default one)
video_capture = cv2.VideoCapture(0)
# Load a sample picture and learn how to recognize it.
# ivan_image = face_recognition.load_image_file("ivan.jpg")
ivan_image = face_recognition.load_image_file("images/train/Ivan/1.jpg")
ivan_face_encoding = face_recognition.face_encodings(ivan_image)[0]
# Load a second sample picture and learn how to recognize it.
# maja_image = face_recognition.load_image_file("maja.jpg")
maja_image = face_recognition.load_image_file("images/train/Maja/3.jpg")
maja_face_encoding = face_recognition.face_encodings(maja_image)[0]
# Create arrays of known face encodings and their names
known_face_encodings = [
ivan_face_encoding,
maja_face_encoding
]
known_face_names = [
"Ivan",
"Maja"
]
# Initialize some variables
face_locations = []
face_encodings = []
face_names = []
process_this_frame = True
while True:
# Grab a single frame of video
ret, frame = video_capture.read()
# Resize frame of video to 1/4 size for faster face recognition processing
small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)
# Convert the image from BGR color (which OpenCV uses) to RGB color (which face_recognition uses)
rgb_small_frame = small_frame[:, :, ::-1]
# Only process every other frame of video to save time
if process_this_frame:
# Find all the faces and face encodings in the current frame of video
face_locations = face_recognition.face_locations(rgb_small_frame)
face_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations)
face_names = []
for face_encoding in face_encodings:
# See if the face is a match for the known face(s)
matches = face_recognition.compare_faces(known_face_encodings, face_encoding)
name = "Unknown"
# # If a match was found in known_face_encodings, just use the first one.
# if True in matches:
# first_match_index = matches.index(True)
# name = known_face_names[first_match_index]
# Or instead, use the known face with the smallest distance to the new face
face_distances = face_recognition.face_distance(known_face_encodings, face_encoding)
best_match_index = np.argmin(face_distances)
if matches[best_match_index]:
name = known_face_names[best_match_index]
face_names.append(name)
process_this_frame = not process_this_frame
# Display the results
for (top, right, bottom, left), name in zip(face_locations, face_names):
# Scale back up face locations since the frame we detected in was scaled to 1/4 size
top *= 4
right *= 4
bottom *= 4
left *= 4
# Draw a box around the face
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
# Draw a label with a name below the face
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255), cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0, (255, 255, 255), 1)
# Display the resulting image
cv2.imshow('Video', frame)
# Hit 'q' on the keyboard to quit!
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release handle to the webcam
video_capture.release()
cv2.destroyAllWindows()